RFCs: Blueprints of the Internet
Think about it for a second: could the internet exist without standards and protocols? Of course not! Computers need shared rules and agreements to communicate with one another. Even human languages, like English, work much the same way. They function as a kind of communication protocol because we’ve all agreed on words and grammar that carry shared meaning. In both cases, whether among machines or people, communication depends on common understanding.
This is where RFCs come in. They’re the blueprints and proposals that define how the internet operates and how systems interact. In this post, we’ll take a closer look at RFCs and uncover some of the fascinating history behind the internet.
Before we dive in, here’s a quick overview: RFCs, or Requests for Comments, are official documents that explain how Internet technologies work. They outline how systems are expected to behave and interact. Think of them as the reference guides for anyone who wants to build, understand, or improve the Internet.
the Birth of the Internet
The history of the internet is a long and amazing tale — one that deserves its own post (and I’ll probably write about it). But for now, let’s focus on how it all began.
I’m not going to answer “Who invented the Internet?” because that’s the wrong question. The internet didn’t appear overnight; it took decades to mature. Instead, we can highlight the people who played key roles in shaping today’s internet.
It all started in the USA in 1958, when the government created the Advanced Research Projects Agency (ARPA) to fund research in new technologies. Contrary to popular myth, ARPA’s purpose was not mainly defensive. While a system capable of withstanding a major military attack would have been useful, it was not ARPA’s mission. Its first goal was much simpler: to allow researchers at ARPA-funded universities across the country to share their work more easily. Initially, the network was used just for exchanging research papers — email didn’t exist yet and only came later, thanks to Ray Tomlinson.
Computers — or better to say, mainframes back in those days — were gigantic and could fill an entire room. Here’s what an IBM 7090 mainframe looked like in the early 60s:
 Fernando Corbató with MIT’s IBM 7090
Fernando Corbató with MIT’s IBM 7090
Back then, transferring data was nothing like the internet file uploads we know today. First, everything was physical: punch cards or paper tapes had to be loaded manually into machines. Then came magnetic tapes (big reels of tape containing data) which you’d physically transport to other machines:
 Set of punch cards + punched paper tape + magnetic tape
Set of punch cards + punched paper tape + magnetic tape
Since these computers were geographically separated, they needed a way to connect and exchange information reliably and fast. The solution was to develop a packet-switching network, which could send data in small blocks called “packets” that could travel independently across the network and be reassembled at their destination. This system eventually became the ARPANET, the first network to implement packet switching, laying the foundation for the modern internet.
In fact, the first use of the term protocol in a modern data communication context appeared in April 1967, in a memorandum titled “A Protocol for Use in the NPL Data Communications Network”. It was written under the direction of Donald Davies, who pioneered the concept of packet switching.
In 1969, the first message was sent over ARPANET from UCLA to Stanford university. They tried to send the word LOGIN, but only LO made it through before the system crashed. About an hour later, after recovering from the crash, the full message was successfully transmitted.
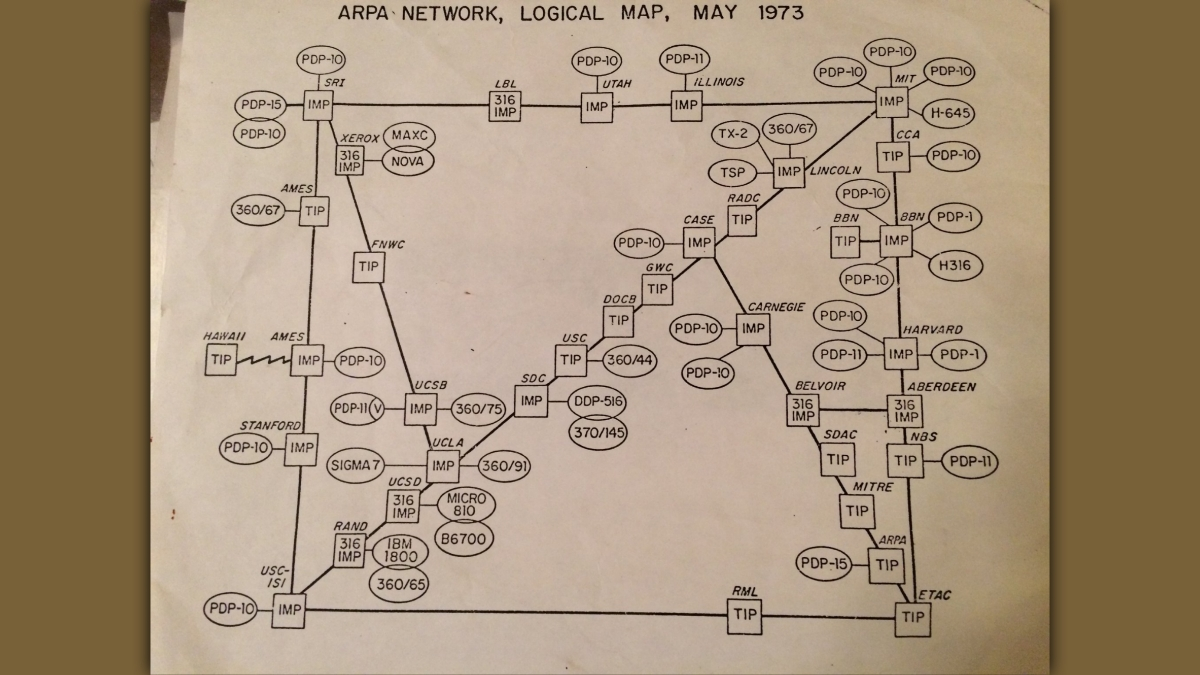
by 1970, there were around 15 nodes (or computers), and by 1972, 19 nodes were connected. In 1973 they even created a map of ARPANET — the same one you see in the post preview image. ARPANET was considered a major success because it showed that packet-switching technology worked in practice and made it possible for distant computers to share information reliably. However, access was still limited to universities and research organizations that held contracts with the U.S. Department of Defense.
As you can see, the network was growing rapidly and that didn’t happen by chance. It was the result of coordination and collaboration. Every node and computer had to follow the same rules and standards to communicate effectively.
By the late 1980s, the foundations laid by ARPANET and early networking experiments made it possible for something revolutionary: in 1989, Tim Berners-Lee proposed the World Wide Web (WWW), which went public in 1991, opening the internet to everyone.
We’ll pause the story of the internet here, having covered the key parts. If you’re interested to know more, you can check out this infographic:
 Internet History Timeline (Infographic from Behance)
Internet History Timeline (Infographic from Behance)
Now it’s time to explore the technical documents that shape and standardize Internet operations.
What Are RFCs?
Request for Comments (RFCs) are a series of numbered documents that describe how the internet works and how different systems communicate. They address a variety of topics, including core standards, communication protocols, guidelines, design ideas, and concepts that help keep the global network running smoothly. Each RFC is written by engineers and computer scientists as a memorandum presenting new ideas, research findings, proposed methods, or other concepts related to internet technologies.
The RFC system was created in 1969 by Steve Crocker to record and share informal notes on the development of ARPANET. The goal was to help researchers share ideas about how the network should operate, how computers (hosts) should communicate, and how software running on these hosts should behave.
The very first RFC, titled “Host Software”, was published by Crocker himself on April 7, 1969. In this context, “host software” referred to the programs and protocols that computers needed to communicate over ARPANET, essentially the foundational rules for networked computing at the time:
 RFC 1: The first Request for Comments document published in 1969
RFC 1: The first Request for Comments document published in 1969
While Steve Crocker authored the first RFC, Jon Postel served as RFC Editor from 1969 until his death. He wrote, co-authored, and carefully managed many foundational RFCs — including those defining TCP/IP and DNS — ensuring the series became the cornerstone of Internet standards. A tribute to him was published as RFC 2468, written by Vint Cerf, highlighting Postel’s immense contributions to the Internet.
Every RFC is assigned a unique number upon publication — starting with RFC 1 — and these numbers are permanent. Once a document receives its number, it never changes or gets reused, even if that RFC later becomes obsolete or is replaced by a newer one. This numbering system helps maintain a consistent historical record of the internet’s evolution and ensures that every RFC can be precisely referenced.
Today, RFCs are maintained and published by the Internet Engineering Task Force (IETF), which continues to develop and expand them. While many RFCs are experimental in nature and never become official standards, others have become the backbone of the Internet’s architecture. These include the core technologies we rely on every day, such as TCP/IP, HTTP, and DNS. RFCs not only define how these protocols operate but also reveal the reasoning behind their design, helping us understand how the global network actually operates.
RFCs are often described as the blueprints of the internet. Yet, in an age where artificial intelligence and higher-level tools make technology more accessible, fewer people explore the underlying systems and details of how things actually work (at least, that’s my perspective). I believe RFCs are essential reading for anyone involved in technology or IT — that’s why I wrote this post.
Why They Still Matter Today?
RFCs remain the official source of truth for Internet standards, ensuring consistency across the global network. By studying them, developers learn not just the rules, but also why they exist, gaining the knowledge needed to build software and systems that communicate reliably with other computers.
You can’t create something truly dependable without understanding its foundations — just as you couldn’t design a beautiful building without knowing architecture, the same principle applies to apps and networked systems.
For instance, if you ever wanted to build your own DNS server, the first step isn’t writing code from scratch or copying an online tutorial. You’d start by reading relevant RFCs, which define the domain name system and how queries and responses should work. By understanding the protocol from the original source, you can ensure your implementation is reliable, interoperable, and standards-compliant. This is the power of RFCs: they let you build on solid foundations rather than reinventing the wheel.
Finding and Reading Them
The official source for RFCs is the RFC Editor, which manages the publication, editing, and archiving of all RFC documents. If you want to explore the development process behind RFCs — including drafts, authors, and approval stages — the IETF Datatracker provides detailed information on every document’s history and current status. Also, for a more comfortable reading experience, RFC Reader offers an online viewer with features like an automatic table of contents, note-taking, and search capabilities.
For guidance on how to read RFCs, the IETF provides a helpful article titled “How to Read an RFC”. I strongly recommend reading it. The article explains how to search for the right documents, understand the structure of RFCs, and identify the most relevant information on the first page.
Some RFCs are informational or experimental, so you should be careful about which ones you read. For example, RFC 1149 literally describes a method for transmitting IP packets using pigeons! Its humorous follow-up, RFC 2549, improves on the idea. You can think of it like something out of a Harry Potter movie — sending messages via birds — but applied, jokingly, to the Internet:
 RFC 1149: IP over Avian Carriers
RFC 1149: IP over Avian Carriers
Also, RFCs are archival documents, which means they cannot be updated once published. As a result, older RFCs may be obsolete or superseded by newer versions, and it’s important to ensure you are reading the correct, up-to-date document. The IETF article linked above explains how to identify the most relevant RFCs and determine which ones are current.
You can also check the references at the end of a Wikipedia article on a given topic, where several related RFCs are often listed for further reading.
When reading these documents, you might come across words like “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL”. These are not just casual suggestions — they have precise and standardized meanings in the context of RFCs. These terms are defined in RFC 2119, which provides guidance for specifying requirement levels in technical documents. Here’s a quick summary of what they mean:
- MUST / MUST NOT / REQUIRED / SHALL / SHALL NOT – Indicates an absolute requirement; the behavior described is mandatory.
- SHOULD / SHOULD NOT / RECOMMENDED – Indicates a strong recommendation, but there may be valid reasons to deviate.
- MAY / OPTIONAL – Indicates a truly optional behavior; implementers have complete discretion.
Understanding these words is crucial because RFCs use them to clearly communicate which rules are mandatory and which are flexible, ensuring interoperability and consistency across the Internet. If you plan to implement protocols, don’t skim RFCs or read them selectively. It’s easy to misinterpret a specification if you only look at part of it. You should read not just the sections that seem directly relevant to what you’re working on, but also any referenced material, to fully understand its requirements.
Final Words
The early developers built much of the technology we rely on today without the Internet or Stack Overflow, relying purely on their skill, curiosity, and persistence. It’s easy to copy and paste something that works — but doing so only makes you one of many. The ones who truly understand are those who push limits and create what has never existed before.
Every protocol, every standard, every “MUST” or “SHOULD” is part of a story crafted by engineers over decades. So don’t be intimidated — explore, read carefully, and let these documents guide you. And if you ever discover a better idea or approach, share it with the world — perhaps even as an RFC. Who knows? The next specification you write could help shape the Internet of tomorrow.
I’ll end this post with a quote from one of my all-time favorite animated films, Ratatouille — a reminder that mastery comes from courage and curiosity:
“You must try things that may not work, and you must not let anyone define your limits because of where you come from. Your only limit is your soul. What I say is true — anyone can cook… but only the fearless can be great.”
Feedback
After sharing this post on Hacker News, I received several interesting suggestions that helped improve the post’s accuracy. One user — who, according to himself, had worked with many of the pioneers of ARPANET — shared insights about the early network that clarified certain points (unfortunately, I forgot to ask for their name). You can read their insights about ARPANET in the comments. Other readers also contributed valuable perspectives, including pointers to notable RFCs such as RFC 1925 (“The Twelve Networking Truths”) and RFC 2468, as well as book recommendations like Where Wizards Stay Up Late, which explores the early history of the Internet.